
Problems of LLM
- Out of date knowledge: the model cannot gain knowledge after training
- Humiliation: the model may generate nonsense output
- Specific domain: the generalized model is difficult to adapt to specific domain
- Enthetic problems: the model may encounter
Fine-tuning
Fine-tuning is used to improve performance of foundation model on specific tasks with the help with some supervised data
Fine-tuning methods can be classified into:
- Based on range of updated parameters:
- Full Model fine-tuning: update the parameters of the whole model
- Partial fine-tuning: freeze the top layer; freeze the bottom layer
- Based on special technology:
- Adapter tuning
- LoRA
- Continual Learning fine-tuning
- Based on input:
- Instruction tuning
- Based on objective
- Multi-task fine-tuning
Problems of fine-tuning:
- Requires task-specific labeled data, may cause overfitting and catastrophic forgetting。
- The generalization ability is limited, and fine-tuning are required when adapting to new tasks
- The performance may be destroyed after fine-tuning, for example, safety.
RAG
RAG consists of three major processes of retrieval, augmentation, and generation. The framework of RAG in LLM can be described as follows:

Retrieval
Retriever type
Retrieval methods can be generally categorized into two types: sparse and dense, based on the information encoding methods.
- sparse retrieval usually relies on inverted index matching along with the raw data input, for example TF-IDF and BM25. The limitation of sparse retrieval in RAG is
- its no-training nature, which makes the retrieval performance heavily rely on the quality of database construction and query generation.
- Moreover, such fixed term-based methods only support similarity retrieval, while cannot be adapted for other retrieval considerations demanding in LLM applications, such as the diversity
- dense retrieval, on the contrary, embeds the query and documents into continuous vector space with certain criteria, for example, semantic similarity. Examples include BERT, Dense Passage Retriever (DPR), etc.
Retrieval Granularity
Retrieval granularity denotes the retrieval unit in which the corpus is indexed, e.g., document, passage, token, or other levels like entity.
- Chunk retrieval.
- Token retrieval.
- Entity retrieval.
Pre-retrieval and Post-retrieval Enhancement
Pre-retrieval and post retrieval strategies can be added to improve the quality of the retriever.
Pre-retrieval methods include:
- Query rewrite. This method aims to close the gaps between the input text and the needed knowledge in retrieval, to reformulate the original question into a more conducive version to retrieve.
- Query augmentation. This method aims to combine the original query and the preliminary generated outputs as a new query, which is further used to retrieve relevant information from the external database
Post-retrieval enhancement denotes the procedure to process the extracted top-k documents from the retriever before feeding them to the generator for the sake of better alignment between the retrieval and generation stages.
Database
- Wikipedia
- Domain specific database
- search engine
Generation
- Parameter-Accessible Generators (White-box). Allow parameter optimization.
- Parameter-Inaccessible Generators (Black-box). Focus more on retrieval and augmentation processes, trying to enhance the generator by augmenting the input with better knowledge, guidances or examples for the generation.
Augmentation
- Input layer integration
- Output layer integration
- Intermediate layer integration
Retrieval Frequency
If it is necessary to retrieve? Self-RAG
retrieval frequency:
- One-time.
- Every-n-token
- Every token
RAG training
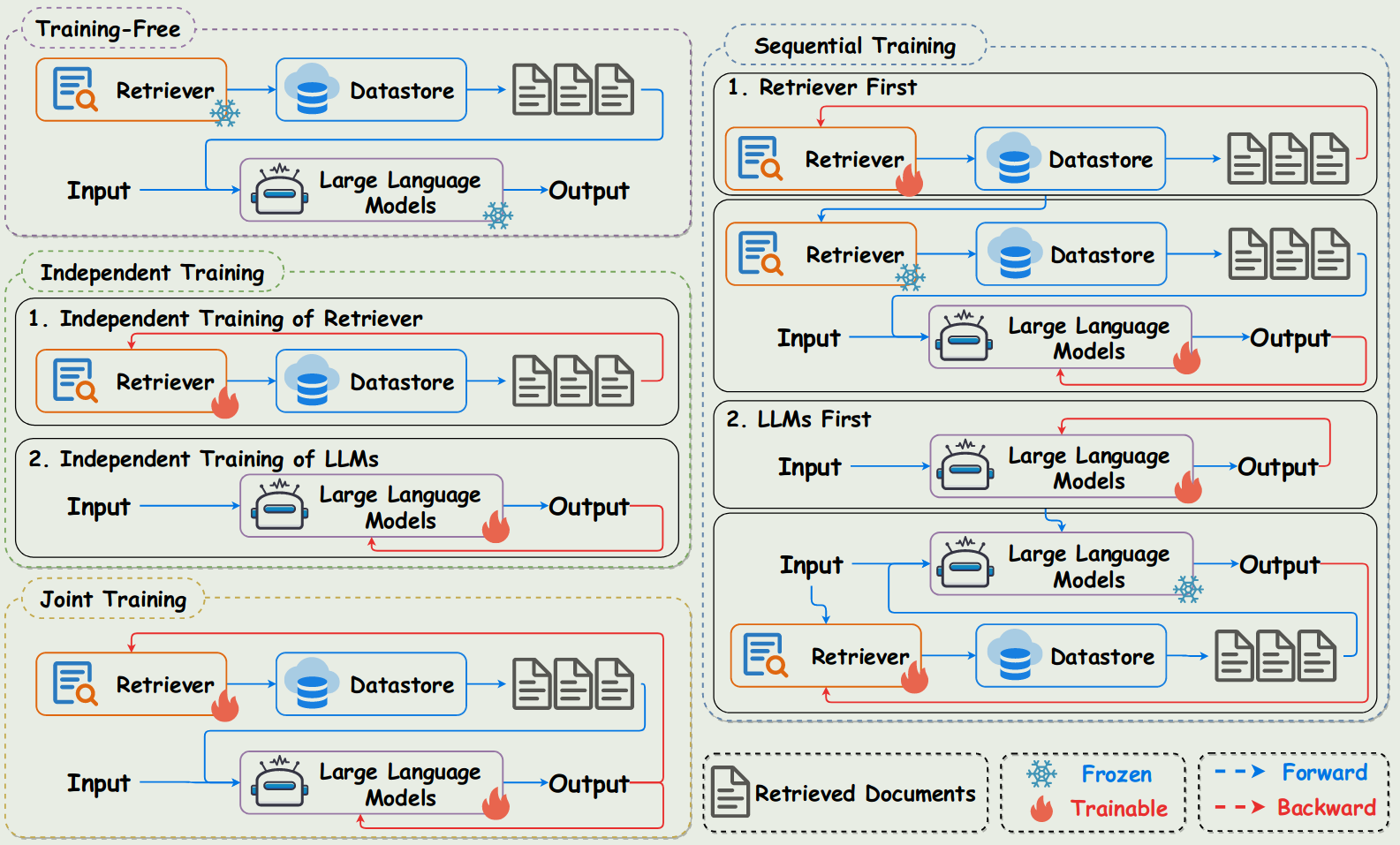
- Training Free
- Independent training
- Sequential training
- Joint training
Advance RAG
Module RAG
Applications
- NLP applications
- QA systems: REALM
- Chatbot:
- Fact Verification: self-RAG
- Downstream tasks:
- Recommendations
- Software engineering
- Domain-specific Applications
- AI for science
- Finance: ChatDOC
Limitations of RAG
Long Context Window
Advantages of Long Context Window:
- Improve the understanding and relativity: long context window allows model to refer to more context information when generating answers.
- Handling complex tasks: long context window makes handling complex tasks such as writing a long article, coding
- Improve users’ experience: the user expects the model remember the chat history and use them to interact with the user.
Disadvantages of long context window:
- Only uses context once, Requires refeeding the data to use long context window.
- Cost expensive due to input price.
- Time expensive due to limit of tokens per second.
- Needle in HayStack experiment show that there are problems with long context window.
Advantages of RAG:
- Privacy projection.
- Allow chunking the texts and retrieve the related information more accurately
- Adaptive to the size of data.
- Accepts multiple type of data source (multimodality).
- Only uses a small part of the total data, which is cheaper compared with long context window .
problems of RAG
- The quality of retrieval
- The retrieved text cannot be aligned with the queried text.
- The queried text are not retrieved all.
- Redundancy or out-dated data may cause inaccuracy.
- the quality of response generation
- Model Humiliation
- Irrelevance
- Organize the output to make it reasonable
- Depends on the external information
Futures:
- Trustworthy RA-LLMs
- Multi-lingual RA-LLMs
- Multi-modal RA-LLMs
- Quality of External Knowledge
Other technologies
- Query transformations
- Sentence window retrieval
- Fusion retrieval/ hybrid search
- multi-document agents